5 データフレームの基本的操作
5.2 データの読み込み
調査や実験などで得たデータはテキストファイルやExcelファイルなど様々な形で保存されています。R でデータ分析を行うには、まずそれらのデータを R に読み込む必要があります。
データのファイル形式としてはテキストファイルやバイナリファイル、Excel や XML、SAS や SPSSのデータ、SQL などのデータベース、あるいは画像ファイルの場合もあるでしょう。R ではこれら様々なデータ形式を読み込むことが可能です。
このセクションではテキストファイルとエクセルファイルの読み込み方法について解説します。
5.2.1 ファイル名に拡張子が表示されるようにする
Windows でも Mac でも、パソコン内のファイル名に拡張子が表示されない設定になっています。これは良くないことなので、まだ拡張子を表示する設定にしていない人は設定を変更しましょう。
5.2.2 データセットについて
このページではdatariumという名前のRパッケージに入っているデータセットを用います。
このパッケージに含まれるデータセットの一覧は以下のページから確認できます。
https://rpkgs.datanovia.com/datarium/index.html
まずはConsoleで以下の命令を実行してdatariumパッケージをインストールしてください。
5.2.3 サンプルデータの準備
Rに読み込むデータとして以下のものを使います。
各ファイルを右クリックから保存し、dataset という名前のフォルダを作ってそこに入れておいて下さい。
このdatasetフォルダを置く場所はパソコン内のどこでも良いですが、今回使用するRスクリプトがある場所と同じ場所(同じフォルダ内)に入れておくと良いでしょう。
下図は job.txt ファイルの中身(一部)です。
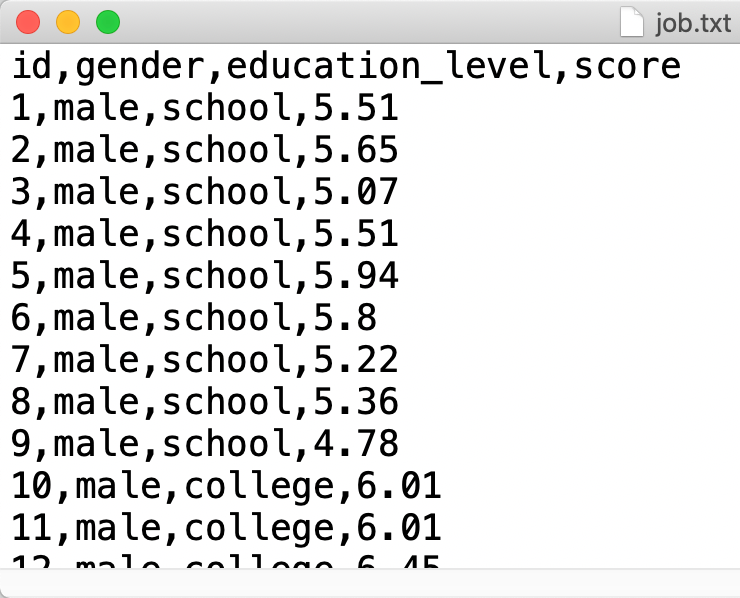
このデータは datarium パッケージに含まれている jobsatisfaction という名前のデータです。
このデータをテキストファイル(txt, csv, tsv)やエクセルファイル(xlsx)に保存したものです。
テキストファイルとは中身が文字だけのファイルのことです。拡張子は txt や csv や tsv など。
csv (comma-separated values): データをコンマ記号で区切ったテキストファイル。
tsv (tab-separated values): データをタブ記号で区切ったテキストファイル。
データをダウンロードしたら、まずはデータの中身を見てみてください。
エクセル版のデータをエクセルで開くと表形式で表示できてわかりやすいです。
データを見ると、
id列は人物の通し番号、
gender列はその人物の性別、
education_level列はその人物の学歴(school, college, universityの3種類)、
score列は仕事満足度の点数
であることがわかります。
5.2.4 テキストファイルの読み込み
テキストファイルを読み込むにはread.table()関数を使います。
読み込むデータの形式に合わせてsepオプションの指定を調整します。
csv形式のデータを読み込む際は以下のようにします。
# csv ファイルの読み込み
data = read.table(file = "dataset/job.csv", header = T, sep = ",", stringsAsFactors = F)
# データの確認
str(data)
## 'data.frame': 58 obs. of 4 variables:
## $ id : int 1 2 3 4 5 6 7 8 9 10 ...
## $ gender : chr "male" "male" "male" "male" ...
## $ education_level: chr "school" "school" "school" "school" ...
## $ score : num 5.51 5.65 5.07 5.51 5.94 5.8 5.22 5.36 4.78 6.01 ...
head(data)
## id gender education_level score
## 1 1 male school 5.51
## 2 2 male school 5.65
## 3 3 male school 5.07
## 4 4 male school 5.51
## 5 5 male school 5.94
## 6 6 male school 5.80str関数を用いて中身を確認すると、id列は数値型(整数)、gender列とeducation_level列は文字列型、score列は数値型であることがわかります。
Console ではなくスクリプトファイルに記述して実行する場合は上記の赤字の内容は表示されません。変数の中身を出力するにはprint関数を使ってください。つまり、 print(str(data)) や print(head(data)) のように記述すると、スクリプトを実行した際にConsole欄に結果が出力されます。
txtやcsv形式のデータを読み込む際は以下のようにします。
# txt ファイルの読み込み
data = read.table(file = "dataset/job.txt", header = T, sep = ",", stringsAsFactors = F)# tsv ファイルの読み込み
data = read.table(file = "dataset/job.tsv", header = T, sep = "\t", stringsAsFactors = F)dataという名前の変数に、データフレームとしてファイルの内容が読み込まれます。
read.table()関数の引数の意味は以下の通りです。
- file: 読み込むファイルのパスを指定する。
- header: 読み込むファイルの1行目が変数名の行なら TRUE にする。
- sep: データの区切り文字(separator)を指定する。
- stringAsFactors: 文字データを要因型に変換する場合は TRUE、文字列型にする場合は FALSE にする。
file 引数について、上記の例ではカレントディレクトリ(getwd() 命令を実行して表示される場所)に dataset というフォルダを作成し、そのフォルダ内に job.txt ファイルがある状態を想定しています。
実際にはdatasetフォルダの場所(パス)に合わせてfile引数の値を調整すればdatasetフォルダがパソコン内のどこにあっても問題ありません。datasetフォルダのパスを調べる方法は「windows フォルダ パス コピー」などで検索して調べてください。
header 引数について、このテキストファイルは一行目が変数名の行になっているので TRUE にします。一行目に変数名がなく、最初の行からデータの中身が始まるファイルの場合には FALSE にします。
sep 引数について、区切り文字がコンマ(,)の場合は sep = "," とします。区切り文字がタブの場合は sep = "\t" とします。区切り文字がスペースの場合は sep = " " とします。
read.table()関数には他にも様々な引数があります。詳しくは help を確認して下さい。
RStudio の Console に? read.tableと打って実行すると関数のヘルプ画面が表示されます。
この例で使った job.txt、job.csv、job.tsv の3つのファイルは実質的に同じものです。
txt ファイルと csv ファイルは拡張子が異なるだけでファイルの中身は同一ですし、tsvファイルは区切り文字がコンマの代わりにタブが使われているだけです。
結果的に、read.table() 関数を使って読み込まれたデータ(データフレーム)はどのファイルを読み込んだ場合でも同一の内容になります。
5.2.5 Excel ファイルの読み込み
エクセル形式のファイルを直接読み込むにはパッケージを使います。openxlsx、xlsx、XLConnect など、エクセルの読み込み用の R パッケージはいくつかありますが、openxlsx 以外のパッケージは Java のインストールも必要になるため、ここでは openxlsx を使うことにします。
まずはパッケージをインストールします。Console で次の命令を実行してください。
次にパッケージを読み込みます。これは Console で実行しても良いし、スクリプトファイルに記述して実行しても構いません。
read.xlsx() 関数を使ってエクセルファイルを読み込みます。
パッケージの読み込みも含めてスクリプトファイルに記述した例を以下に示します。
library(openxlsx)
data = read.xlsx("dataset/job.xlsx")
head(data)
## id gender education_level score
## 1 1 male school 5.51
## 2 2 male school 5.65
## 3 3 male school 5.07
## 4 4 male school 5.51
## 5 5 male school 5.94
## 6 6 male school 5.80エクセルファイルを読み込む別の方法として、エクセルを使ってエクセルファイルを txt や csv などのテキスト形式のファイルとして出力し、それを5.2.4の方法でテキストファイルとして読み込むことも可能です。
5.3 データフレームの利用
まずはこのセクションで使うデータを用意します。
以下の例ではテキストファイルやエクセルファイルからデータを読み込むのではなく、datariumパッケージに含まれるデータをそのまま用いています。 datariumパッケージを読み込むことでjobsatisfactionという名前のデータが使用可能になります。
最初にも説明したように、このjobsatisfactionのデータは上のセクションで読み込んでいたテキストファイルやエクセルファイルと中身は同じです。
jobsatisfactionという変数名は長くて扱いにくいので、jobという変数に代入しました。
as.data.frameの箇所は、jobsatisfactionはtibbleというデータ型をしているので、それをデータフレーム型に変換しています。
str関数を用いて中身を確認してみます。
str(job)
## 'data.frame': 58 obs. of 4 variables:
## $ id : Factor w/ 58 levels "1","2","3","4",..: 1 2 3 4 5 6 7 8 9 10 ...
## $ gender : Factor w/ 2 levels "male","female": 1 1 1 1 1 1 1 1 1 1 ...
## $ education_level: Factor w/ 3 levels "school","college",..: 1 1 1 1 1 1 1 1 1 2 ...
## $ score : num 5.51 5.65 5.07 5.51 5.94 5.8 5.22 5.36 4.78 6.01 ...id, gender, education_level列が因子型として読み込まれています。
テキストファイルを読み込んだ場合と同様のデータ型にするには以下のようにします。
job$id = as.numeric(job$id)
job$gender = as.character(job$gender)
job$education_level = as.character(job$education_level)
str(job)
## 'data.frame': 58 obs. of 4 variables:
## $ id : num 1 2 3 4 5 6 7 8 9 10 ...
## $ gender : chr "male" "male" "male" "male" ...
## $ education_level: chr "school" "school" "school" "school" ...
## $ score : num 5.51 5.65 5.07 5.51 5.94 5.8 5.22 5.36 4.78 6.01 ...idとscoreは数値型、genderとeducation_levelは文字列型になりました。
job は 58 行・4 列のデータフレームです。
ベクトルとデータフレーム
用意した元データ(job変数)から分析のために何らかのデータを抽出する際には、以下の2つの場合があります。
- 元データから特定の条件を満たすデータをベクトルとして抽出する
- 元データから特定の条件を満たすデータをデータフレームとして抽出する
ベクトルとして抽出した場合は、そのベクトルの平均値などの計算に利用することが多いでしょう。
データフレームとして抽出した場合は、そのデータフレームをさらに加工したり、作図に利用したりすることが多いでしょう。
5.3.1 $ 記法を使ったベクトルの抽出
データフレームでは $ 記号を使うと特定の列をベクトルとして取り出せます。
# score列のベクトルを得る
x = job$score
print(x)
## [1] 5.51 5.65 5.07 5.51 5.94 5.80 5.22 5.36 4.78 6.01 6.01 6.45
## [13] 6.45 6.38 6.74 6.09 6.30 5.58 9.13 9.28 8.84 9.28 10.00 10.00
## [25] 9.57 8.99 9.13 8.70 5.80 5.94 5.22 5.65 6.38 6.38 6.09 5.51
## [37] 5.51 4.93 6.52 6.67 5.94 6.38 7.10 7.10 6.81 6.23 6.23 5.65
## [49] 8.26 8.41 9.13 9.57 9.42 8.84 8.55 7.97 6.52 7.39
# scoreの3番目の要素を得る
x = job$score[3]
print(x)
## [1] 5.07table関数を使ってデータの要約を行うことができます。
print(table(job$gender))
##
## female male
## 30 28
print(table(job$education_level))
##
## college school university
## 19 19 20このデータには男性が30人、女性が28人だとわかります。
また、学歴は短大19人、高校19人、大学20人だとわかります。
さて、jobの1行目から28行目までが男性のデータなので、男性のスコアの平均値を計算するには次のようにすれば計算できます。
上記の例では男性のみのスコアを抽出するために1:28という行指定を手作業で行いました。しかし、抽出したい行のインデックスがいつでも簡単に分かるわけではありません。たとえば、何万行もあるデータの場合に抽出したい行のインデックスを目で見て確認することは困難です。他にも、学歴が大学である行だけを抽出したい場合などは、該当する行が全て連続した場所にあるわけではないので、該当する行のインデックスの数値を手作業で指定するのが面倒になります。
そこで、次のような方法で特定の条件を満たすデータを抽出します。
==演算子を使ったデータ抽出
条件に一致した値のみを抽出する際は、== 演算子を使います。
# gender が "male" であるかどうかを示すベクトル
job$gender == "male"
## [1] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
## [13] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
## [25] TRUE TRUE TRUE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [37] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [49] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSEこの論理値ベクトルをインデックスとして使うと、条件に一致した行が抽出できます。
# gender が "male" である行の score のベクトル
maleScore = job$score[job$gender == "male"]
print(maleScore)
## [1] 5.51 5.65 5.07 5.51 5.94 5.80 5.22 5.36 4.78 6.01 6.01 6.45
## [13] 6.45 6.38 6.74 6.09 6.30 5.58 9.13 9.28 8.84 9.28 10.00 10.00
## [25] 9.57 8.99 9.13 8.70学歴が大学であるデータを抽出するには以下のようにします。
今回は抽出したいインデックスをindexという名前の変数にセットしています。
# 学歴が大学の行のみの score を得る
index = job$education_level == "university"
univScore = job$score[index]
print(univScore)
## [1] 9.13 9.28 8.84 9.28 10.00 10.00 9.57 8.99 9.13 8.70 8.26 8.41
## [13] 9.13 9.57 9.42 8.84 8.55 7.97 6.52 7.39複数の条件を同時に満たすデータを抽出したい場合は、==演算子の式を&でつなぎます。
たとえば、男性かつ大学卒という条件に一致するデータを抽出するには以下のようにします。
index = job$gender == "male" & job$education_level == "university"
maleUnivScore = job$score[index]
print(maleUnivScore)
## [1] 9.13 9.28 8.84 9.28 10.00 10.00 9.57 8.99 9.13 8.70
print(mean(maleUnivScore))
## [1] 9.292男性かつ大学卒の人物の平均仕事満足度は9.292であることがわかります。
補足:データフレームからベクトルを抽出する別の記法
(初学者はこの補足は飛ばしてよい)
$記号を使わずに、他の方法でベクトルを抽出することもできます。
[]を使って行と列を指定したり、[[ ]]を使って列を抽出できます。
4と書いているのは、score列が4番目の列だからです。
これらの記法を使って、スコアデータの1行目から3行目のみを抽出するには次のようにします。
# この5つは同じこと(スコアデータのうち最初の3つ分の値を抽出)
job$score[1:3]
job[1:3, "score"]
job[1:3, 4]
job[["score"]][1:3]
job[[4]][1:3]上記の1:3の箇所をjob$gender == "male"などに書き換えることで、男性のみのスコアデータを抽出することも同様に可能です。
いろいろな記法があることを紹介しましたが、基本的には$を使った方法だけ使えば良いでしょう。
ただし、列名を文字列として指定できることが便利な場合もあります。
列名を変数に格納し、プログラムでその変数の内容(列名)を動的に変更できるからです。
5.3.2 subset() 関数を用いたデータフレームの抽出
subset() 関数を使うことで元データから特定の行や列のみを含むデータフレームを作成できます。
この関数はsubset(x, subset, select) という引数を持ちます。
第1引数は処理したいデータフレームです。
subset 引数による行の指定
subset 引数には抽出したい行の条件式を入れます。
# education_level が "university" である行だけのデータフレームを作成
df = subset(job, subset = education_level == "university")
# 男性かつ大学卒である行だけのデータフレームを作成
df = subset(job, subset = gender == "male" & education_level == "university")%in% 演算子を使った例。
# education_level が "college" または "university" であるデータフレームを作成
df = subset(job, subset = education_level %in% c("college", "university"))> 演算子を使った例。
# score が9.5以上の行のみのデータフレームを作成
df = subset(job, subset = score >= 9.5)
print(df)
## id gender education_level score
## 23 23 male university 10.00
## 24 24 male university 10.00
## 25 25 male university 9.57
## 52 52 female university 9.57
# score が9以上または5未満の行のみのデータフレームを作成
df = subset(job, subset = score >= 9.5 | score < 5)
print(df)
## id gender education_level score
## 9 9 male school 4.78
## 23 23 male university 10.00
## 24 24 male university 10.00
## 25 25 male university 9.57
## 38 38 female school 4.93
## 52 52 female university 9.57
subset 引数に入れる条件式においては $ 記号は使う必要はありません。つまり、
subset( job, subset = job$score > 9 )
といった書き方をする必要はありません(そう書いてもエラーにはならず同じ結果が得られますが)。
select 引数による列の指定
select 引数を使うと特定の列を抽出できます。
# gender の列のみのデータフレームを得る
df = subset(job, select = gender)
print(head(df, 3))
## gender
## 1 male
## 2 male
## 3 male
# 列名を引用符で囲う必要はない(そう書いてもエラーにはならないし同じ結果が得られるが)
df = subset(job, select = "gender")
# gender と score の列のみのデータフレームを得る
df = subset(job, select = c(gender, score))
print(head(df, 3))
## gender score
## 1 male 5.51
## 2 male 5.65
## 3 male 5.07便利な記法として、マイナス記号を使うことで特定の列の除外を行うことができます。
# 元のjobデータを確認
print(head(job, 3))
## id gender education_level score
## 1 1 male school 5.51
## 2 2 male school 5.65
## 3 3 male school 5.07
# gender列を除外したデータフレームを得る
df = subset(job, select = -gender)
print(head(df, 3))
## id education_level score
## 1 1 school 5.51
## 2 2 school 5.65
## 3 3 school 5.07
# id列とeducation_level列を除外したデータフレームを得る
df = subset(job, select = -c(id, education_level))
print(head(df, 3))
## gender score
## 1 male 5.51
## 2 male 5.65
## 3 male 5.07データフレームに不要な列がありそれを捨てたい場合などに便利です。
特定の列をデータフレームから削除したい場合は列に NULL を代入する方法もあります。
以下の2つは同じ結果になります。
5.3.3 データ抽出のまとめ
性別が female で、学歴が university である人のscore の平均値を計算する、という状況を想定してデータ抽出方法についてまとめておきます。データ準備の部分もまとめて掲載しています。
library(datarium)
# データの準備
job = jobsatisfaction
job = as.data.frame(job)
job$id = as.numeric(job$id)
job$gender = as.character(job$gender)
job$education_level = as.character(job$education_level)
# ベクトルを抽出して計算する
index = job$gender == "female" & job$education_level == "university"
v = job$score[index]
print(mean(v))
## [1] 8.406
# データフレームを作成して計算する
index = job$gender == "female" & job$education_level == "university"
df = subset(job, subset = index)
print(mean(df$score))
## [1] 8.406同じことをするのに複数のやり方があるのはややこしいことなのですが、どの書き方も R ではよく使われるので慣れておく必要があります。
5.4 データフレームの基本的な編集
5.4.1 データフレームの列順の並べ替え
job データは id, gender, education_level, socre という順で列が並んでいます。
何らかの理由でその並び順を変えたい場合は、以下のようにします。
# 現在の job データ
print(head(job, 3))
## id gender education_level score
## 1 1 male school 5.51
## 2 2 male school 5.65
## 3 3 male school 5.07
# 列を指定した順番に並び替える
cnames = c("id", "education_level", "gender", "score")
dat = job[, c( cnames, setdiff(names(job), cnames))]
print(head(dat, 3))
## id education_level gender score
## 1 1 school male 5.51
## 2 2 school male 5.65
## 3 3 school male 5.07
# socre と gender を先頭に移動させ、それ以外の列はそのまま後ろにつなげる場合
cnames = c("score", "gender")
dat = job[, c(cnames, setdiff(names(job), cnames))]
print(head(dat, 3))
## score gender id education_level
## 1 5.51 male 1 school
## 2 5.65 male 2 school
## 3 5.07 male 3 school並び替え後の列名のベクトルを作り(ここでは変数名を cnames としてます)、setdiff 関数を利用して並べ替え後の列名ベクトルを作成しています。
データフレームの列を並べ替える操作はよく行う機会があるので、関数を作っておくと便利でしょう。以下ではreorderDFという関数を作成し、引数に元のデータフレームと並べ替え後の列名ベクトルを与えることで、変換後のデータフレームが得られるようにしています。
5.4.2 結合
複数のデータフレームを結合する方法について説明します。
横方向の結合および縦方向の結合があります。
5.4.2.1 横方向の結合 cbind
例として以下のような df1 と df2 という2つのデータフレームがあったとします。
df1 = data.frame(id = 1:3, name = c("Alice", "Bob", "Charles"))
print(df1)
## id name
## 1 1 Alice
## 2 2 Bob
## 3 3 Charles
df2 = data.frame(age = c(10, 20, 30), gender = c("female", "male", "male"))
print(df2)
## age gender
## 1 10 female
## 2 20 male
## 3 30 malecbind() 関数を使ってこれらを横方向に結合できます。
df = cbind(df1, df2)
print(df)
## id name age gender
## 1 1 Alice 10 female
## 2 2 Bob 20 male
## 3 3 Charles 30 maleこの時、df1 と df2 の行数が同じである必要があります(同じでない場合はエラーになる)。
5.4.2.2 縦方向の結合 rbind
例として以下のような df1 と df2 という2つのデータフレームがあったとします。
df1 = data.frame(id = 1:2, name = c("Alice", "Bob"))
print(df1)
## id name
## 1 1 Alice
## 2 2 Bob
df2 = data.frame(id = 3:4, name = c("Charles", "Dick"))
print(df2)
## id name
## 1 3 Charles
## 2 4 Dick次のように、rbind() 関数を使ってこれらを縦方向に結合できます。
異なる列数のデータフレームを縦方向に結合したい場合はdplyrパッケージのbind_rows()関数を使います。
df1 = data.frame(id = 1:2, name = c("Alice", "Bob"), age = c(10, 20))
print(df1)
## id name age
## 1 1 Alice 10
## 2 2 Bob 20
df2 = data.frame(id = 3:4, name = c("Charles", "Dick"))
print(df2)
## id name
## 1 3 Charles
## 2 4 Dick
library(dplyr)
df = bind_rows(df1, df2)
print(df)
## id name age
## 1 1 Alice 10
## 2 2 Bob 20
## 3 3 Charles NA
## 4 4 Dick NAdf2にはage列がないので、結合後のdfにおいてNAがセットされています。
dplyrパッケージをまだインストールしていない場合は、Console で install.packages("dplyr") という命令を実行してインストールをしてください。
5.5 確認問題
5.5.1 read.table関数の引数
CSVファイルの一行目に「変数名(列名)」が書かれている場合、read.table() 関数で正しく読み込むために指定すべき引数はどれですか。
- header = TRUE
- header = FALSE
- sep = TRUE
- stringsAsFactors = TRUE
解答
解答は1。
ファイルの一行目がデータそのものではなく、各列の名前である場合は header = TRUE を指定します。FALSE にすると一行目もデータの一部として読み込まれてしまいます。
5.5.2 stringsAsFactors の役割
read.table() 関数には stringsAsFactors という引数があります。この引数を FALSE に設定した場合、テキストファイル内の文字データはどの型として読み込まれますか。
- factor (因子型)
- character (文字列型)
- numeric (数値型)
- logical (論理値型)
解答
解答は2。
stringsAsFactors = TRUE にすると文字データは自動的に「因子型」に変換されますが、FALSE に指定することでそのまま「文字列型」として読み込むことができます。
5.5.3 データ抽出の記法
データフレーム df にある score 列を、ベクトルとして取り出すための正しい書き方はどれですか。
- df[score]
- df(score)
- df$score
- df.score
解答
解答は3。
- Rのデータフレームでは $ 記号を使うことで、特定の列をベクトルとして抽出できます。
df["score"]のように引用符をつければ[]でも抽出可能ですが、選択肢1のように引用符がない場合はエラーになります。
5.5.4 subset 関数の条件指定
subset() 関数を使って、df というデータフレームの「gender 列が "female" である行」のみを抽出したいとします。正しい書き方はどれですか。
subset(df, subset = gender = "female")subset(df, subset = gender == "female")subset(df, select = gender == "female")subset(df, subset = df$gender == "female")
解答
解答は2と4。
- 条件の一致を判定するには等号一つ(=)ではなく、比較演算子(==)を使う必要があります。
- また、行の抽出条件を指定する引数は select ではなく subset です(select は列の選択に使います)。
- 2 の書き方をするのが普通ですが、4 でも同じ結果が得られます。
5.5.5 結合関数の要件
cbind() 関数を使って2つのデータフレームを「横方向」に結合する場合、満たしていなければならない条件はどれですか。
- 両方のデータフレームの「行数」が同じであること
- 両方のデータフレームの「列数」が同じであること
- 両方のデータフレームの「列名」が同じであること
- データの値がすべて数値であること
解答
解答は1。
- 横にデータをつなげるため、縦の長さ(行数)が揃っている必要があります。
- なお、行方向(縦方向)に結合する rbind() の場合は列の構成が揃っている必要があります。
5.5.6 bind_rows の挙動
dplyr パッケージの bind_rows() 関数を使って、列の構成が一部異なる2つのデータフレームを縦方向に結合しました。片方のデータにしか存在しない列の値は、結合後にどうなりますか。
- 自動的に 0 で埋められる
- 自動的に NA(欠損値)が入る
- エラーが発生して結合できない
- その列自体が削除される
解答
解答は2。
デフォルトの R で使える rbind() 関数では列数が異なるとエラーになりますが、dplyr パッケージの bind_rows() 関数では、不足しているデータを NA で補完して結合してくれます。
5.5.7 CSVファイルの読み込み
まず、以下のコードを実行して、カレントディレクトリ(Console でgetwd()を実行して表示される場所)に test.csv というファイルを作成してください。
# 問題用ファイルの作成
df_dummy = data.frame(id = 1:3, val = c(10, 20, 30))
write.table(df_dummy, "test.csv", sep = ",", row.names = FALSE, quote = FALSE)この test.csv ファイルを、read.table() 関数を使って読み込み、変数 dat に格納するコードを書いてください。
5.5.8 TSVファイルの読み込み
上の問題と同様に、以下のコードを実行してタブ区切りのファイル test.tsv を作成してください。
このファイルを read.table() 関数を使って正しく読み込むコードを書いてください。
5.5.10 複数条件(AND)での抽出
以下のようなデータフレーム dat があります。
「年齢(age)が20、かつ、性別(gender)が "female"」である行の score を抽出するコードを書いてください。
dat = data.frame(
age = c(20, 20, 30, 30),
gender = c("male", "female", "male", "female"),
score = c(80, 90, 70, 60)
)解答
# 条件式の作成
index = dat$age == 20 & dat$gender == "female"
# 抽出
dat$score[index]
## [1] 90
# このような抽出方法も可能
dat[index,]$score
## [1] 90
# subset関数を使う場合
subset(dat, subset = (age == 20 & gender == "female"), select = score)
## score
## 2 90
# このような書き方もできる
subset(dat, subset = (age == 20 & gender == "female"))$score
## [1] 90
- 2つの条件を同時に満たすデータを探す場合は & 演算子を使います。「条件A & 条件B」と記述します。
- 上記の回答では index という変数に抽出したい行のベクトルを格納していますが、そのような中間変数を作成せず、以下のようにして直接抽出処理を行っても構いません。
dat$score[dat$age == 20 & dat$gender == "female"]- subset 関数を使うのも良いでしょう。select 引数を使って score 列のみを持つデータフレームを作成しています。あるいは最後の方法のように、subset() 関数の後に $ 記号を使って score 列をベクトルとして取り出すこともできます。
5.5.11 複数条件(OR)での抽出
以下のデータフレーム dat から、「score が 80以上、または、score が 40未満」である行のみを抽出した新しいデータフレームを作成してください。
解答
# subset関数を使う場合
dat2 = subset(dat, subset = score >= 80 | score < 40)
# 条件式を使って抽出したい行を指定する場合
dat2 = dat[dat$score >= 80 | dat$score < 40, ]
- 「または」の条件を指定するには | 演算子を使います。
- subset() 関数の中では dat$ を付ける必要がなく、列名をそのまま記述できます。
- 2番目の方法の場合、コンマ(
,)をつけ忘れないように気をつけます。dat という変数はベクトルではなくデータフレーム(行と列を持つ)なので、[]記号を使ってインデックスを指定する際はコンマを入れて行と列のインデックスを指示する必要があります。今回の場合は行だけを指定して列は何も指定していません(その場合はすべての列が指定される)。
5.5.12 subset による列の選択
以下のデータフレーム dat から、subset() 関数を使って id 列と score 列のみを選択(抽出)し、dat2 という変数に格納してください。
5.5.14 列の並べ替え
以下のデータフレーム dat の列の順番を、name, id の順に入れ替えてください。
解答
# 元のデータ
dat = data.frame(id = 1:3, name = c("A", "B", "C"))
print(dat2)
## id score
## 1 1 70
## 2 2 80
## 3 3 90
# 並べ替え
dat = dat[, c("name", "id")]
print(dat)
## name id
## 1 A 1
## 2 B 2
## 3 C 3
- データフレームの列順を変えるには、
df[, c("列名1", "列名2")]のように、欲しい順番で列名を指定して抽出します。 - データフレームの列の数が少ない場合、本文中で紹介した方法よりもこのようなシンプルな方法の方が分かりやすいでしょう。