13 データ可視化の演習
13.2 ジュエリーブランドの仕入れ戦略の検討
13.2.1 シナリオ
あなたはとあるジュエリーブランドの専属バイヤーです。
これまで、あなたのブランドでは「最高品質こそ正義」と考え、ダイヤモンドのカット(研磨)グレードが最高ランク「Ideal(理想的)」 のものだけを仕入れていました。しかし、最近の円安や原材料費の高騰により、仕入れコストが圧迫されています。高い販売価格のままでは顧客が離れてしまう恐れがあります。
そこであなたは次のような仮説を立てました。
- 「最高ランクの Ideal にこだわらなくても、その一つ下のランク Premium や Very Good の中には、見た目の輝きやサイズ感(カラット)が変わらず、価格が安い『お買い得な石』があるのではないか?」
この仮説を検証し、
- Ideal グレード以外の仕入れを検討すべきか?
- 検討すべきなら、どのグレードが狙い目か?
を判断するためのデータ分析を行なってください。
13.2.2 使用するデータセット:diamonds
Rの ggplot2 パッケージに標準で含まれている diamonds データセットを使用します。これは約54,000個のダイヤモンドの価格と品質に関するデータです。
このデータの中の特に重要な列を以下に示します。
- carat : ダイヤモンドの重さ。サイズ感に直結する。
- cut : カットの質。順に Fair, Good, Very Good, Premium, Ideal の5段階。
- color : ダイヤモンドの色(J:最悪 〜 D:最良)。
- clarity : 透明度(I1:最悪 〜 IF:最良)。
- price : 価格(米ドル)。今回の最重要変数。
上記の列にある Carat/Cut/Color/Clarity はどれもCで始まる単語であり、まとめて「4C」と呼ばれます。4C はダイヤモンドの品質を評価するための国際基準となっています。
ダイヤモンドを選ぶ品質評価国際基準“4C”
https://www.brilliance.co.jp/engagement/select/criterion.html
13.2.3 STEP 1:データの全体像を把握する
データ分析の第一歩は、手元のデータがどのような状態かを知ることです。まずはデータの全体像を把握しましょう。
【問題】
- diamonds データセットを読み込み、内容を表示させてください。このデータセットにはどのような列が含まれているかを確認してください。また、このデータセットが全部で何行(何個のダイヤモンド)あるかを確認してください。
- 今回注目している変数 cut(カットの質・ランク)には、具体的にどのような種類の値が含まれているか、その内訳(各ランクの個数)を確認してください。
【ヒント】
- データの読み込み:
library(ggplot2)を実行した上で、dat = diamondsなどとして変数datにデータを入れておくと便利です。 - データを確認する: RStudio の Environment タブにあるデータフレーム変数をクリックすればデータの中身を表形式で表示できます。
- データの概要や内訳を把握する際は
table()関数やsummary()関数が便利です。
検索のヒント わからない場合は、以下のキーワードでGoogle検索してみましょう。
「R データフレーム 確認」
「R 列の種類 確認」
「R summary 使い方」
「R table関数 使い方」
解答と解説(クリックして展開)
# デーの準備
library(ggplot2)
dat = ggplot2::diamonds # dat = diamonds でもOK。
# cut の内訳を確認
table(dat$cut)
##
## Fair Good Very Good Premium Ideal
## 1610 4906 12082 13791 21551
# summary関数を使う場合
summary(dat)
## carat cut color clarity depth
## Min. :0.2000 Fair : 1610 D: 6775 SI1 :13065 Min. :43.00
## 1st Qu.:0.4000 Good : 4906 E: 9797 VS2 :12258 1st Qu.:61.00
## Median :0.7000 Very Good:12082 F: 9542 SI2 : 9194 Median :61.80
## Mean :0.7979 Premium :13791 G:11292 VS1 : 8171 Mean :61.75
## 3rd Qu.:1.0400 Ideal :21551 H: 8304 VVS2 : 5066 3rd Qu.:62.50
## Max. :5.0100 I: 5422 VVS1 : 3655 Max. :79.00
## J: 2808 (Other): 2531
## table price x y
## Min. :43.00 Min. : 326 Min. : 0.000 Min. : 0.000
## 1st Qu.:56.00 1st Qu.: 950 1st Qu.: 4.710 1st Qu.: 4.720
## Median :57.00 Median : 2401 Median : 5.700 Median : 5.710
## Mean :57.46 Mean : 3933 Mean : 5.731 Mean : 5.735
## 3rd Qu.:59.00 3rd Qu.: 5324 3rd Qu.: 6.540 3rd Qu.: 6.540
## Max. :95.00 Max. :18823 Max. :10.740 Max. :58.900
##
## z
## Min. : 0.000
## 1st Qu.: 2.910
## Median : 3.530
## Mean : 3.539
## 3rd Qu.: 4.040
## Max. :31.800
## [解説]
- RStudio の Environment の欄にある dat 変数の箇所に 53940 obs. of 10 variables と表示されています。53940 個分の行(観測: observations)があり、10 個の列があることがわかります。行数や列数を数値として取り出したい場合は
dim(dat)やnrow(dat)を実行してみてください。 table()関数はデータの特定の列の内訳を調べる際に便利です。データフレームのすべての列の内訳や分布を知りたい場合はsummary()関数を使います。summary()関数の出力の中の cut の箇所を見てください。(当然ですが、)table()関数を使った場合と同じ内訳の数値が表示されています。summary()関数は、数値型である列に対しては四分位数を出力します。四分位数とは何か、調べて理解しておいてください。
13.2.4 STEP 2:可視化の方針を考える
【問題】
今回の分析では「同じサイズ感(カラット)でも、Cut の違いによって価格がどう変わるか」を知ることが重要だと言えます。データを可視化してこれを知るためには、どのような図を作ることが効果的でしょうか?
- グラフの種類(geom): データの分布や2変数の関係性を見るのに適したグラフは何か?
- X軸(横軸): 何の変数を置くべきか?(原因や独立変数を置くのが一般的です)
- Y軸(縦軸): 何の変数を置くべきか?(結果や従属変数を置くのが一般的です)
- 比較の方法: cut の違いを表現するために、どのような美的属性(aes)を使うのが効果的か?(色? 形? それ以外?)
解答と解説(クリックして展開)
- グラフの種類 (geom) : 散布図 (geom_point) を使います。carat と price という2つの数値型の変数の間にどのような関連性があるかを見るのに最も適しています。
- X軸 (横軸) : carat を指定します。今回は「このサイズの石に対していくら払うべきか」を考えたいので、サイズが原因ないしは要因だとみなせます。
- Y軸 (縦軸) : price を指定します。価格はサイズや品質(カット)の「結果」として決まるので、Y軸に配置するのが自然です。
- 比較の方法 : 色分けしたり、cut ごとにグラフを分割(facet機能)するのが効果的だと考えられます。
13.2.5 STEP 3:グラフの作成
STEP 2 の方針に基づいてグラフを作成します。データ量の多さにより生じる問題に対処し、また cut グレードごとの比較がしやすいようなグラフを作成しましょう。
グラフを見て、データにどのような特徴が見られるかを考えましょう。
解答と解説(クリックして展開)
fig = ggplot(dat, aes(x = carat, y = price, color = cut)) +
geom_point(alpha = 0.1) +
facet_wrap(~ cut) +
theme_bw() +
labs(
x = "カラット (Carat)",
y = "価格 (Price / USD)",
color = "カット品質"
)
plot(fig)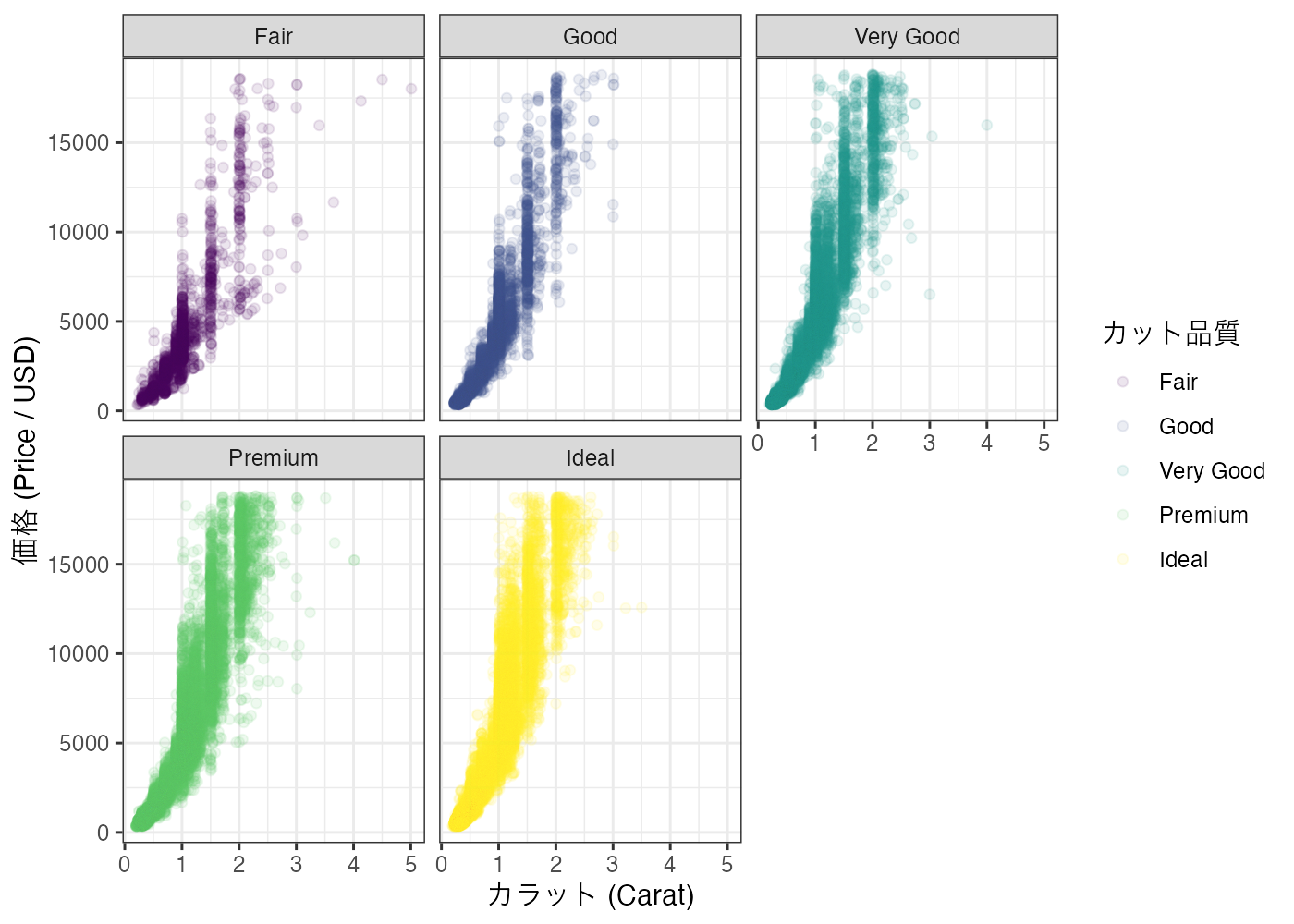
[解説]
以下のような作図の工夫を行なっています。
alpha = 0.1として点をかなり薄くすることで、大量の点の密度をわかりやすくしています。- cut を色でマッピングするだけだと、大量の点が混ざり合ってグラフが読み取りにくいです。そこで、cut でグラフを分割して表示し、比較しやすくしています。
グラフから以下のような特徴が見て取れます。
- 価格トレンドの確認: どのパネル(cut グレード)でも、carat が増えるほど price が上昇するという基本的なトレンド(傾向)が見て取れます。
- Ideal vs. Premiumの価格帯の重複: 特に 1.0 カラット未満のゾーンや、多くのデータが密集するゾーンで、Ideal の価格帯と Premium の価格帯がY軸方向(価格)に大きく重なり合っていることが分かります。
13.2.6 STEP 4:意思決定を行なう
【問題】可視化の結果に基づいて、以下の問いに対する考えをまとめてください。
- 最高ランクの Ideal と、その下の Premium や Very Good を比較したとき、同じカラット数(例えば 1カラット〜1.5カラット付近)での価格分布に決定的な断絶(明らかな価格差)はありますか? それともかなり重複していますか?
- 冒頭の仮説「ランクを少し下げても、安くて良い石があるのではないか?」は支持できそうですか?
- バイヤーとして、今後 Ideal 以外で積極的に仕入れを検討すべきグレードはどれですか? その理由は?
【ヒント】
- 正解は一つではありません。グラフから読み取れる事実(データの分布)をもとに、論理的に説明できていればOKです。
- 例えば、「Premiumグレードの1.5カラット付近を見ると、Idealの同サイズよりも明らかに安い価格帯の個体が多く存在する」といった読み方をします。
解答と解説(クリックして展開)
1. 価格分布における断絶の有無
回答:断絶はありません。価格帯は大きく「重複」しています。
特に、多くの取引が行われる1.0カラット以下のゾーンや、1.0カラット台の石を比較すると、Ideal グレードの最低価格帯と Premium グレードの最高価格帯がY軸方向(価格)でとてもよく重なり合っています。
これは、同じ 8,000 USDを支払う場合でも、Ideal グレードの石を買うこともできれば、Premium グレードの石を買うこともできることを意味します。
2. 仮説の支持
回答:仮説「ランクを少し下げても、安くて良い石があるのではないか?」は支持されます。
グラフから、「同じ価格帯で、Ideal よりもカラットが大きい(見た目が良い)Premium の石を入手可能である」ことや、「同じカラットで、Ideal よりも安価な Premium や Very Good の石を入手可能である」ことがわかります。
3. 今後の仕入れにおける推奨グレード
回答:PremiumまたはVery Good グレード
Premium や Very Good グレードは、Ideal と価格重複が大きく、また Ideal よりも低い価格の石も多く存在します。Premium グレードであれば、顧客の視覚的な満足度を落とさずに、Ideal を仕入れるよりも仕入れコストを下げることができそうです。Very Good グレードであれば Ideal や Premium よりも低価格帯の石が入手できるかもしれませんが、最高品質を重視するというブランドのコンセプトからは少し離れてしまうかもしれません。
13.2.7 追加問題
ダイヤモンドを評価する 4C の中でも、肉眼でその違いが判別しやすいものはカラット(重量・サイズ)とカット(輝き)です。そこで、上記の分析ではこの2つに着目しました。
しかし、ダイヤモンドのクラリティ (clarity) は内包物の少なさを表すため、このグレードが低すぎると、カットが良くても輝きや美観が損なわれる可能性があります。ブランドとしては、「価格を抑えつつ、顧客が肉眼で内包物に気づかないレベルの最低限の品質」を確保したいと考えています。
【問題】
clarity の影響を考慮に入れ、仕入れ戦略について再度検討してください。
【ヒント】
- clarity の順序関係は
head(dat$clarity)とすると表示されます。
Levels: I1 < SI2 < SI1 < VS2 < VS1 < VVS2 < VVS1 < IF
I1 が最もグレードが低く、IF が最もグレードが高い。宝石業界では一般的に、VS2(Very Slightly Included 2) 以上のクラリティであれば、訓練を受けていない人が肉眼で内包物を発見することは非常に困難だとされています。 - 今回は cut ではなく clarity を使ってグラフを分割すると、クラリティごとの価格傾向の違いを検討できます。
- この問題はあまりはっきりした解答はありません。また、グラフのみから確定的な結論を導くことも難しいでしょう。この問題を検討するための図を書くことができればそれでOKと考えてもらえばよいです。
解答と解説(クリックして展開)
fig = ggplot(dat, aes(x = carat, y = price, color = cut)) +
geom_point(alpha = 0.1) +
facet_wrap(~ clarity, nrow = 2) +
theme_bw() +
labs(
x = "カラット (Carat)",
y = "価格 (Price / USD)",
color = "カット品質"
)
plot(fig)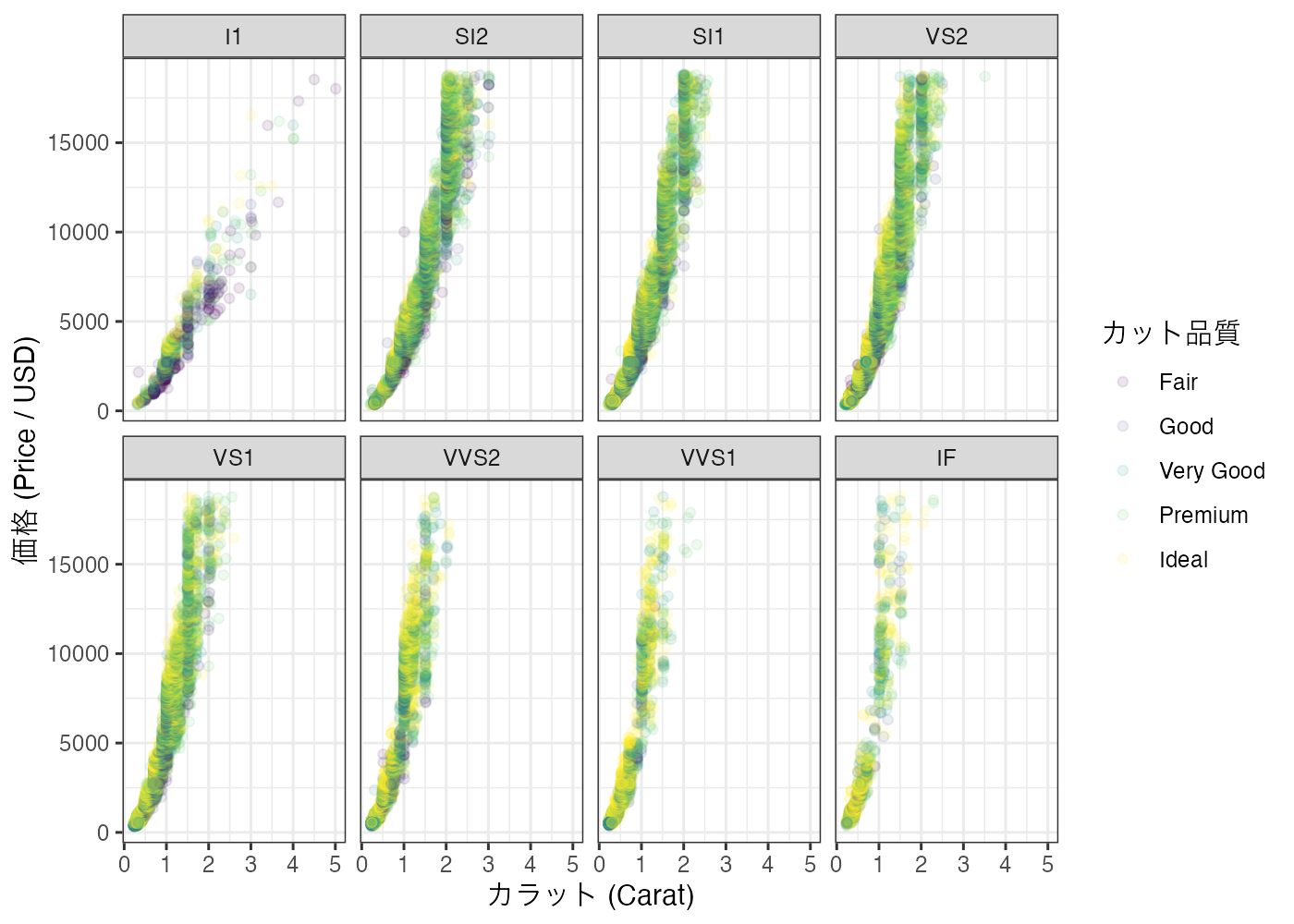
[解説]
グラフから読み取れること:
- クラリティが高いゾーン(IF, VVS1, VVS2): このゾーンでは、Ideal、Premium、Very Good の間で価格差が大きく、Ideal は特に高い価格帯の石が目立ちます。
- クラリティが中間〜低いゾーン(VS1, VS2, SI1, SI2, I1): クラリティが下がるにつれて、Ideal と Premium の価格差は縮まる傾向にあります。VS2 や その前後のパネルでは、Ideal の価格帯が Premium の価格帯に大きく飲み込まれている(重複がさらに増えている)ことがわかります。
13.3 不動産市場のトレンドとリスク評価
13.3.1 シナリオ
あなたは、テキサス州の不動産市場に特化した投資ファンドのリサーチ・アナリストです。次の四半期に向けて、投資予算を州内の主要都市に配分する計画を立てています。
過去のデータに基づき、Houston、Dallas、Austin の3都市を評価し、以下の2つの質問に答えるための分析材料を用意することがミッションです。
- リターン(価格成長)の評価: どの都市が最も高い価格成長トレンドを示しているか?
- リスク(市場健全性)の評価: 成長率が高い都市の市場は、販売数(実需)を伴って健全に伸びているか?
13.3.2 使用するデータセット:txhousing
このデータセットには、テキサス州内の都市における住宅販売に関する月次データが含まれています。2000年から2015年までの期間をカバーしており、不動産市場の動向を追うのに適しています。Rの ggplot2 パッケージに標準で含まれているデータセットです。
このデータセットの列について:
- city : 対象となる都市名(地域別比較の軸)
- year : 年
- month : 月
- sales : 月間販売数(取引件数)。販売数が多いほど市場は活発です。
- volume : 月間総売上額(米ドル)。販売された住宅の総取引価値。
- median : 住宅の中心価格(中央値、米ドル)。投資リターン、価格変動のトレンドを示す指標です。
- listings : 月間新規掲載数。市場への新規供給量を表します。
- inventory : 在庫月数(売れ残り在庫が何ヶ月で解消されるか)
- date : 年・月を小数値で表現したもの。回帰分析や数値処理に便利だが、可視化には向かない。
13.3.3 データの準備
時系列分析を行うには、year(年)と month(月)の情報を組み合わせた日付の列が必要です。以下のスクリプトを使って、日付の情報を Date 型で表現した date_ymd 列を追加してください。
13.3.4 STEP 1:主要3都市の価格トレンド比較
【問題】
- 投資リターンを評価するため、Houston、Dallas、Austin の3都市の住宅の中心価格 (median) の推移を比較する折れ線グラフを作成してください。
- 作成したグラフに基づき、「3都市の中で最も高い価格成長を示している都市はどこか?」、「価格変動が最も安定している都市はどこか?」という問題に答えてください。
【ヒント】
- 元のデータセットから、上記3都市のデータのみをフィルタリングするとよい。
- X軸には date_ymd を使う。
- X軸にDate型の値を指定した場合、軸調整には
scale_x_date()関数を使います。 - 線の色を city で色分けする際は、aes() の中で
color=cityだけでなくgroup=cityも指定するとよい。
解答と解説(クリックして展開)
library(ggplot2)
dat = txhousing
# 日付用の列の追加 (YYYY-MM-DD形式)
date_ymd = paste(dat$year, dat$month, "01", sep="-")
dat$date_ymd = as.Date(date_ymd, format="%Y-%m-%d")
# フィルタリング: Houston, Dallas, Austin の3都市に絞り込み、dfに格納
df = dat[dat$city %in% c("Houston", "Dallas", "Austin"), ]
# グラフの作成
fig = ggplot(df, aes(x = date_ymd, y = median, color = city, group = city)) +
geom_line(linewidth = 0.9) +
scale_x_date(
date_breaks = "3 years", date_labels = "%Y",
limits = c(as.Date("2000-01-01"), as.Date("2016-01-01")),
expand = c(0, 0)
) +
labs(x = "日付", y = "中心価格 (USD)") +
theme_classic() +
theme(
panel.grid.major = element_line(color = "gray90", linewidth = 0.5),
panel.grid.minor = element_blank()
)
# グラフを表示
plot(fig)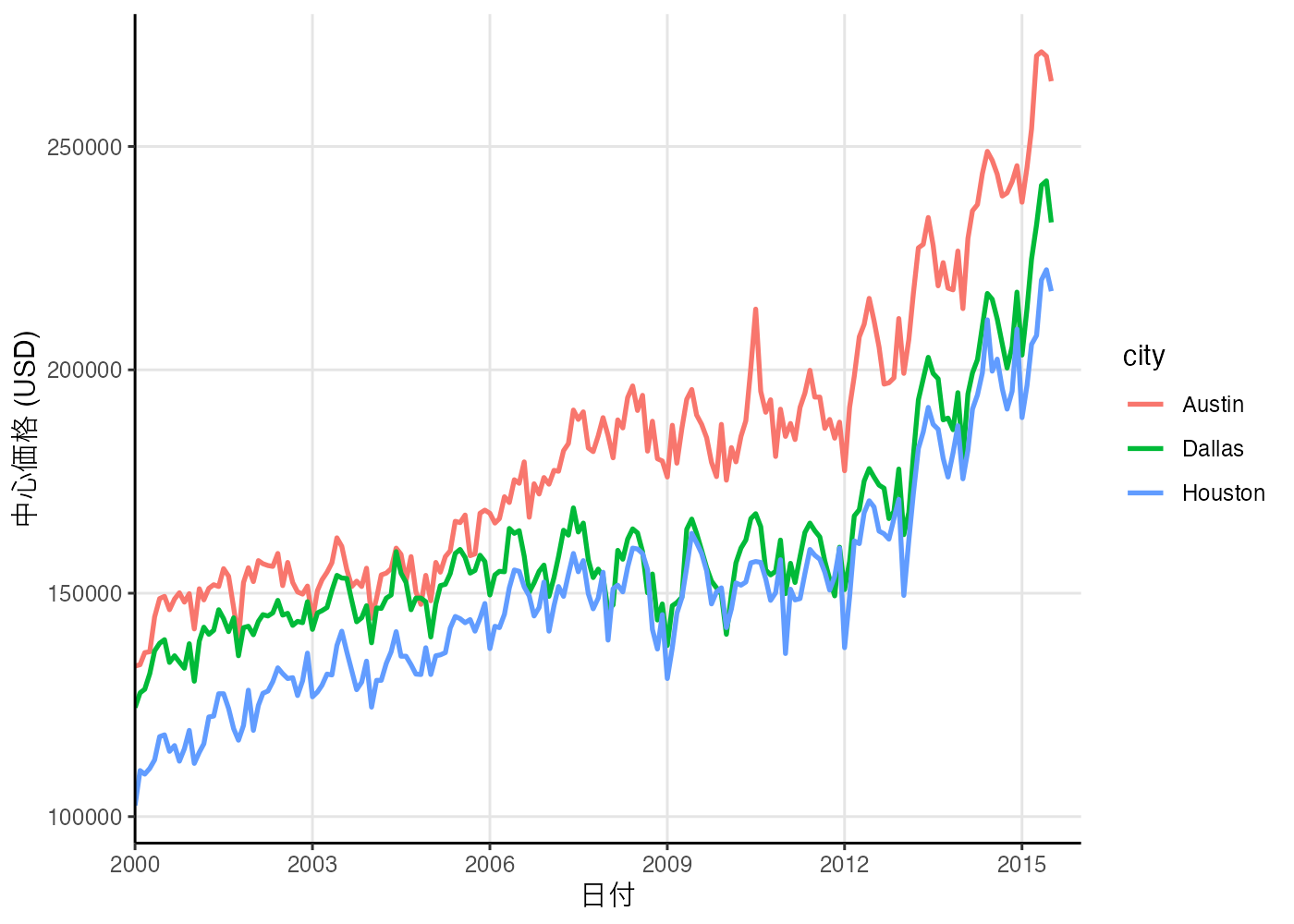
[作図の解説]
日付型のX軸を制御するために scale_x_date() 関数を使います。
date_breaks と date_labels:
date_breaks = "3 years"で目盛りの間隔を3年ごとに設定。date_labels = "%Y"で表示形式を年(例:2000, 2003, …)に指定しています。
limits と expand:
limits = c(as.Date("2000-01-01"), ...): X軸の描画開始点を明示的に2000年1月1日に固定し、目盛りの基準点を設定しています。expand = c(0, 0): 軸の余白をゼロに設定します。これにより、limits で指定した開始点(2000年)から軸の目盛りが開始されます。
テーマの調整
panel.grid.major: element_line(color = "gray90", ...): theme_classic() を使うとグリッド線が消えますが、今回の図ではグリッド線があった方が良いと判断し、追加しています。panel.grid.minor = element_blank(): 補助的なグリッドラインを削除し、グラフのノイズを減らしています。
[図の解釈]
- 最も高い価格成長率を示している都市 (リターン評価)
- 回答: Austin(オースティン)
- 理由: グラフの線が他の2都市よりも最終到達点が高く、傾きが急です。2006年以降、Austinは他の都市よりも明確に先行して価格が上昇しており、その傾向は2015年時点でも継続中です。
- 価格変動が最も安定している都市 (リスク評価)
- 回答: Austin(オースティン)
- 理由: リーマンショック後の2009年頃に Dallas や Houston は大きく価格が下落しています。同じ時期に Austin も下落しているものの、下落幅は比較的小さいです。したがって、この3都市の中では Austin が最も価格の変動が小さく、安定している都市であると考えられます。
13.3.5 STEP 2:ターゲット都市の市場健全性分析
STEP 1の分析から、Austin が「最も高い価格成長」と「最も高い安定性」を兼ね備えた理想的な投資ターゲットであることが判明しました。そこで、その価格上昇が投機的な加熱ではなく、実需によって支えられた健全なものであるかを検証したいと考えました。
【問題】
Austinのデータのみを抽出し、以下の2つの時系列折れ線グラフを作成してください。
- 価格の推移 : X軸 date_ymd、Y軸 median
- 販売数の推移: X軸 date_ymd、Y軸 sales
これら2つのグラフを比較し、価格上昇が実需の増加によって裏付けられているか、つまり、「価格 (median) の上昇が販売数 (sales) の増加を伴っているか」を検討してください。
【ヒント】
2つのグラフを見比べやすくするためには patchwork を使ってグラフを結合するとよいでしょう。
解答と解説(クリックして展開)
library(ggplot2)
library(patchwork) # グラフの結合のために使用
dat = txhousing
# 日付用の列の追加 (YYYY-MM-DD形式)
date_ymd = paste(dat$year, dat$month, "01", sep="-")
dat$date_ymd = as.Date(date_ymd, format="%Y-%m-%d")
# フィルタリング: Austin のデータのみを抽出
df_austin = subset(dat, city == "Austin")
# グラフ 1: 価格 (Median) の推移
p1 = ggplot(df_austin, aes(x = date_ymd, y = median)) +
geom_line(color = "darkblue", linewidth = 0.9) +
scale_x_date(
date_breaks = "3 years", date_labels = "%Y",
limits = c(as.Date("2000-01-01"), as.Date("2016-01-01")),
expand = c(0, 0)
) +
labs(x = "日付 (年)", y = "中心価格 (USD)") +
theme_classic() +
theme(
panel.grid.major = element_line(color = "gray90", linewidth = 0.5),
panel.grid.minor = element_blank()
)
# グラフ 2: 販売数 (Sales) の推移
p2 = ggplot(df_austin, aes(x = date_ymd, y = sales)) +
geom_line(color = "darkred", linewidth = 0.9) +
scale_x_date(
date_breaks = "3 years", date_labels = "%Y",
limits = c(as.Date("2000-01-01"), as.Date("2016-01-01")),
expand = c(0, 0)
) +
labs(x = "日付 (年)", y = "販売数 (件)") +
theme_classic() +
theme(
panel.grid.major = element_line(color = "gray90", linewidth = 0.5),
panel.grid.minor = element_blank()
)
# patchwork で2つのグラフを縦に結合
combined_plot = p1 / p2
# 結合したグラフを表示
plot(combined_plot)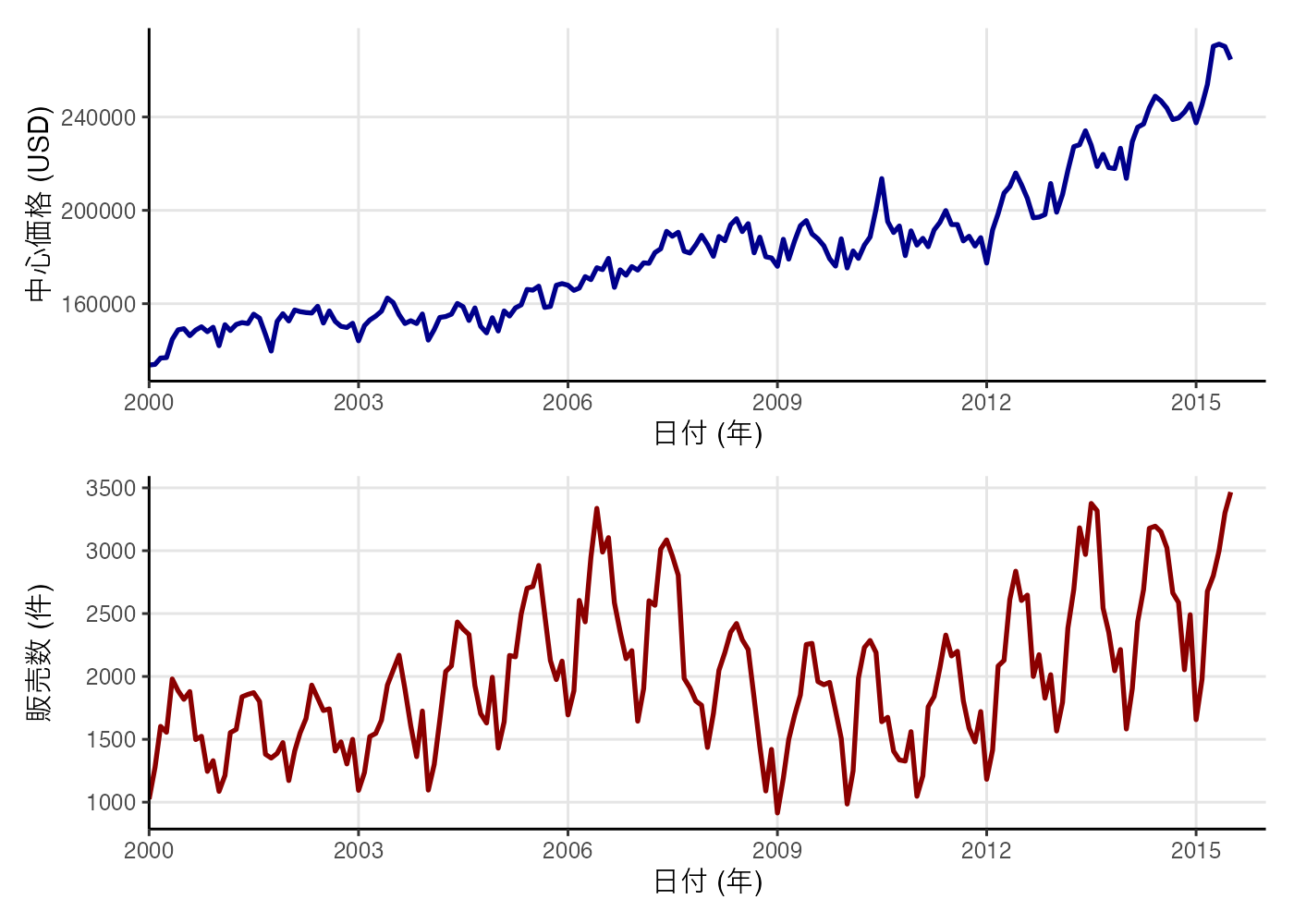
[解説]
作図について
- 2つのグラフで scale_x_date に同じ設定をすることで、図を結合した際に軸が揃うようになり、比較がしやすくなります。
健全性の評価
- 価格は2000年から2008年頃まで穏やかな上昇を続けています。販売数も同じ時期に上昇傾向を示していますが、2007年頃には下落も見られます。
- 販売数は2012年頃以降は上昇傾向にあり、価格も同時期に上昇傾向を示しています。
- 販売数が低迷しているのに価格だけが上昇する(投機的なバブルの兆候)状態は見られず、実際の取引量の増加が価格を押し上げている構造が確認できます。
- 以上の分析から、Austin は投資先として優先すべき都市であると考えられます。
13.4 製品クラス別マーケティング戦略
13.4.1 シナリオ
あなたは大手自動車メーカーのマーケティング戦略担当者です。
消費者の間には「SUVは便利だが、燃費が悪い」という固定観念が根強く残っています。しかし、あなたの会社は燃費効率の高いSUVを開発しました。この顧客の固定観念をデータで検証し、販売戦略を最適化する必要があります。
分析の目標
- 車種クラスごとの燃費効率のばらつきを比較し、固定観念が正しいかを検証する。
- 市場シェアの状況を分析し、自社の SUV をどうアピールすべきかを考える。
13.4.2 使用するデータセット:mpg
このデータセットには、1999年と2008年に米国で販売された人気車種38モデルの燃費データが含まれています。Rの ggplot2 パッケージに標準で含まれているデータセットです。
このデータセットの列について(一部):
- manufacturer: メーカー名。
- class: 車種区分(SUV, compact, midsizeなど)。
- hwy: 高速道路燃費(mile/gallon)。値が大きいほど少ない燃料で多く走れて燃費効率が良い。
- displ: 排気量(リットル)。
- drv: 駆動方式(f:前輪駆動, r:後輪駆動, 4:四輪駆動)。
13.4.3 STEP 1:燃費効率の分布比較と固定観念の検証
車種クラスごとの燃費の比較を通じて、顧客の固定観念がデータで裏付けられるかどうかを検証します。
【問題】
- 車種クラス (class) ごとに高速道路燃費 (hwy) の分布を比較するグラフを作成してください。
- 箱ひげ図 (geom_boxplot) または バイオリンプロット (geom_violin) を作成してください。
グラフから、以下の問いに答えてください。
- 燃費効率が最も良い(中央値が高い)クラスはどれですか?
- 燃費の分布に基づいて、SUVについてどのようなことが言えそうですか?
【ヒント】
- X軸の車種クラスの並び順を、中央値が高い順など意味のある順序に並べ替えることも検討してみてください(reorder() 関数が利用できます)。
解答と解説(クリックして展開)
library(ggplot2)
dat = mpg
# グラフ作成
# reorder()を使って、X軸(class)をY軸(hwy)の中央値(median)が高い順に並べ替える
fig = ggplot(dat, aes(x = reorder(class, hwy, median), y = hwy)) +
geom_boxplot(fill = "#88b5d3", outlier.colour = "gray70") +
labs(x = "車種区分", y = "高速道路燃費 (mpg)") +
scale_y_continuous(limits = c(10, 45), breaks = c(10, 20, 30, 40)) +
theme_bw() +
theme(
axis.title = element_text(size = 16), # 軸ラベルを16ptに
axis.text = element_text(size = 14), # 目盛りを青色に
axis.text.x = element_text(angle = 30, hjust = 1), # X軸のタイトルを少し傾ける
)
# グラフを表示
plot(fig)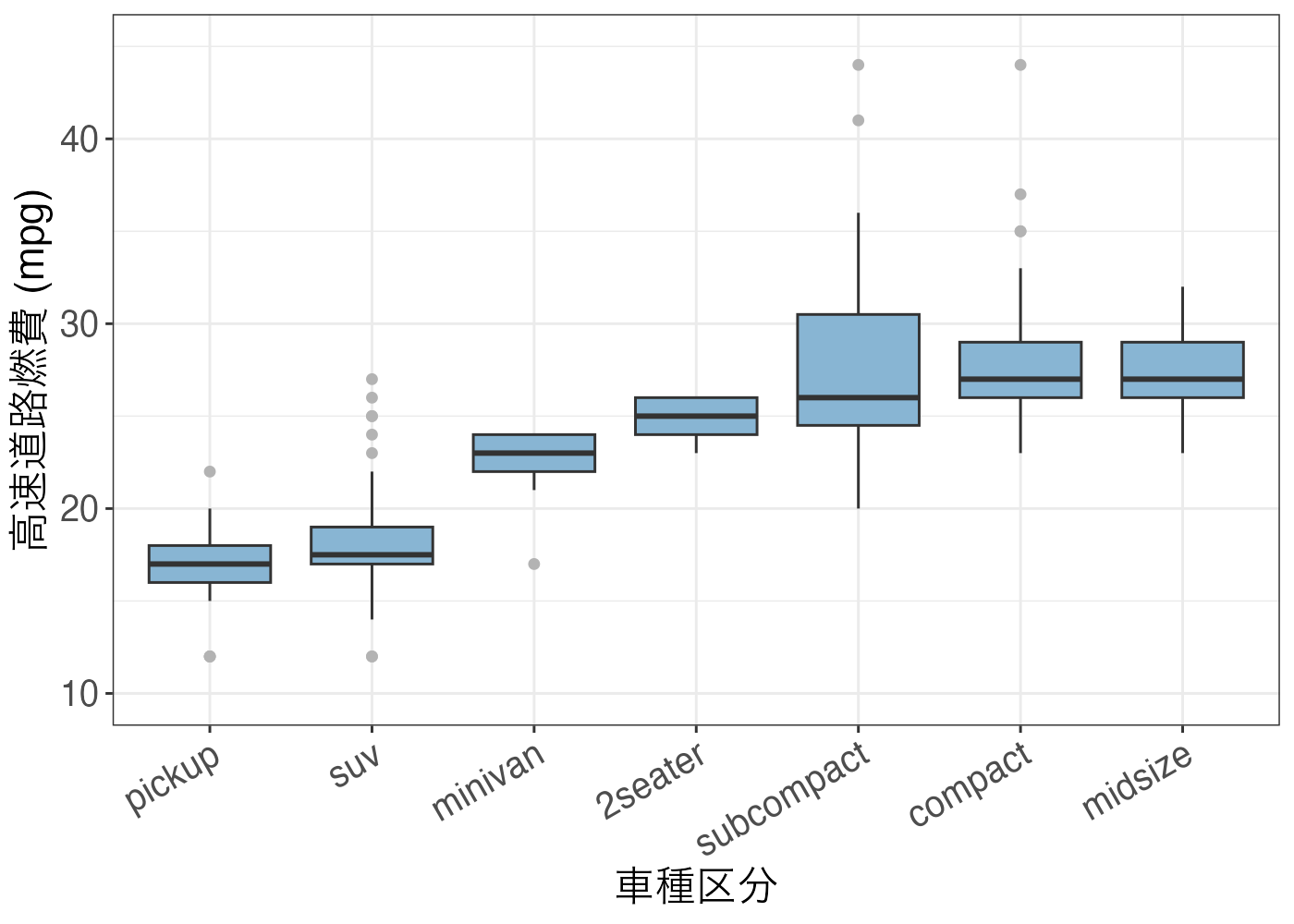
[解説]
reorder() 関数の応用:
aes(x = reorder(class, hwy, median), ...)- X軸のカテゴリ(class)を、Y軸の値(hwy)の中央値 (median) が高い順に並べ替えることで、結果がわかりやすくなります。
燃費効率が最も良い(中央値が高い)クラスはどれか:
- グラフから、midsize や compact の中央値が最も高く、燃費が良いことがわかります。
- また、subcompact はばらつき(箱の高さ = 四分位範囲)が大きく、ミッドサイズやコンパクトカーよりも燃費が良い車が一定数存在することがわかります。
SUVの燃費について:
- SUV の中央値は最下位である pickup の次に低く、「SUVは燃費が悪い」という一般論は確かに事実だと確認できます。
- SUV の四分位範囲はコンパクトカーなどとはまったく重なっておらず、ほとんどの SUV はコンパクトカーより燃費が悪いことがわかります。
- SUV の上側のヒゲはコンパクトカーの下側のヒゲに接近しています。また、SUV の上側の外れ値の中には、コンパクトカーの中央値を超えるものもあります。
以上の結果から、通常の SUV はとても燃費が悪いが、ごく例外的に、コンパクトカーに匹敵する燃費の良さを持った SUV も存在することがわかりました。
バイオリンプロットを用いる場合は以下のようにします。library(ggplot2)
dat = mpg
fig = ggplot(dat, aes(x = reorder(class, hwy, median), y = hwy)) +
geom_violin(fill = "#88b5d3", color = NA, width = 0.7) +
geom_boxplot(width = 0.1, fill = "white") +
labs(x = "車種区分", y = "高速道路燃費 (mpg)") +
scale_y_continuous(limits = c(10, 45), breaks = c(10, 20, 30, 40)) +
theme_bw() +
theme(
axis.title = element_text(size = 16),
axis.text = element_text(size = 14),
axis.text.x = element_text(angle = 30, hjust = 1)
)
plot(fig)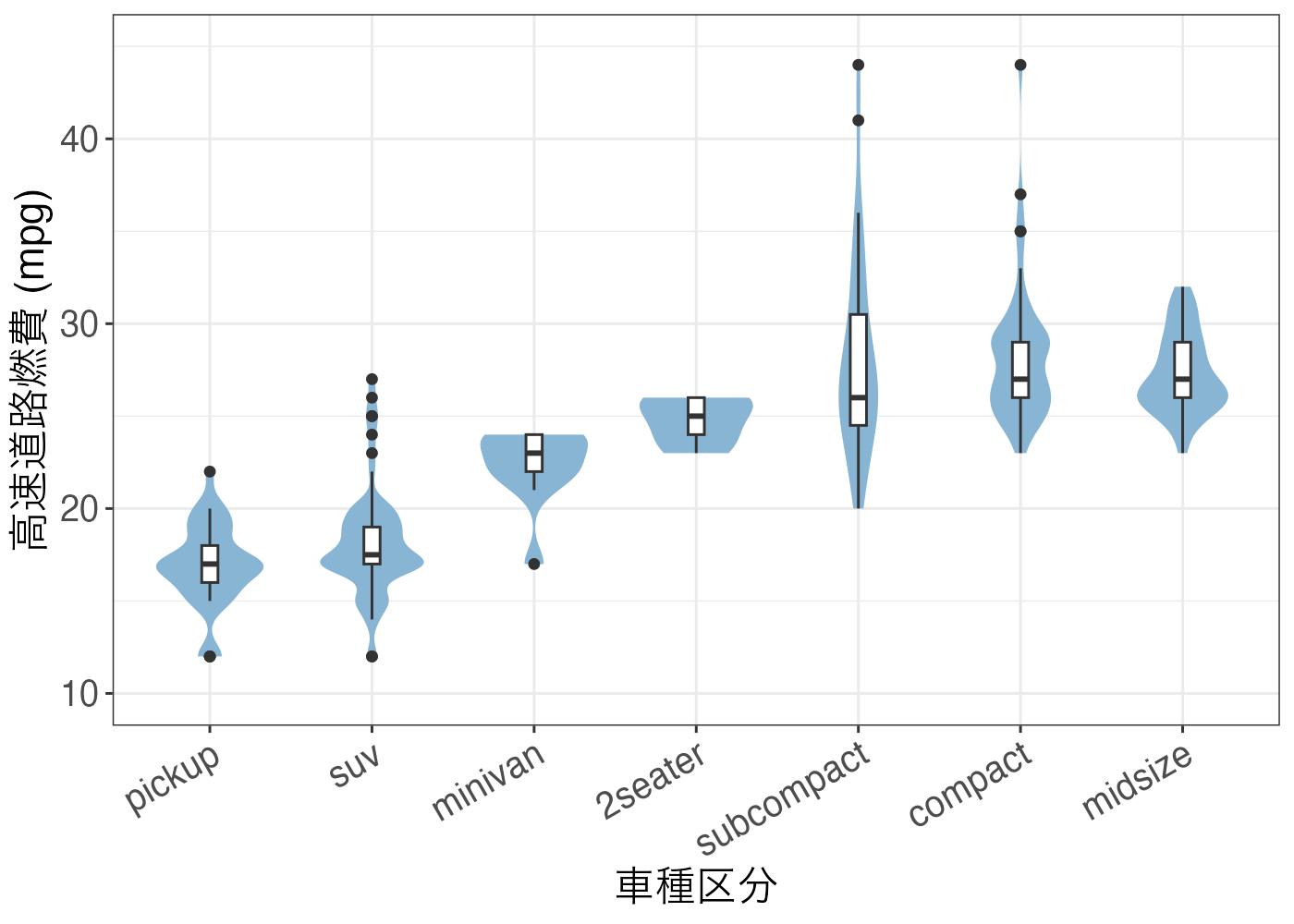
13.4.4 STEP 2:多角的な要因分析と競争状況の把握
燃費に影響を与える要因(駆動方式)と、市場の競争状況(メーカーの勢力図)を分析し、マーケティング戦略の方向性を決定します。
【問題】
課題 A: 駆動方式の影響分析
- 燃費分布が駆動方式 (drv) ごとにどう異なるかを検討するグラフを作成してください。
- 駆動方式によって燃費の良さに違いはあるでしょうか?
- 例外的に燃費の良い SUV 車はどの駆動方式に多く見られますか?
課題 B: 市場の競争状況把握
- メーカー (manufacturer) と 車種区分 (class) ごとに、データセットに含まれる車種の総数をカウントし、集計データを作成してください。
- メーカー別の車種数を車種区分で色分けしたスタック棒グラフを作成し、市場シェアを可視化してください。
- SUV を売り出す際にはどのような企業が競争相手になりそうですか?
【ヒント】
- 課題Aではファセット機能を使うと良いでしょう。
- 課題Bで、メーカーと車種で集計をするには
table(dat$manufacturer, dat$class)とすると良いでしょう。ただし、この処理結果は matrix 型で出力されるので、データフレーム型に変換すると良いでしょう。
解答と解説(クリックして展開)
[課題A]
# STEP 2 課題 A 解答コード
library(ggplot2)
dat = mpg
# グラフ作成: facet_wrap(~drv) を追加
fig_drv = ggplot(dat, aes(x = reorder(class, hwy, median), y = hwy)) +
geom_boxplot(fill = "#88b5d3", outlier.colour = "gray70") +
facet_wrap(~ drv) +
scale_y_continuous(limits = c(10, 45), breaks = c(10, 20, 30, 40)) +
theme_bw() +
labs(x = "車種区分", y = "高速道路燃費 (mpg)") +
theme(
axis.text.x = element_text(angle = 30, hjust = 1),
panel.grid.minor = element_blank()
)
plot(fig_drv)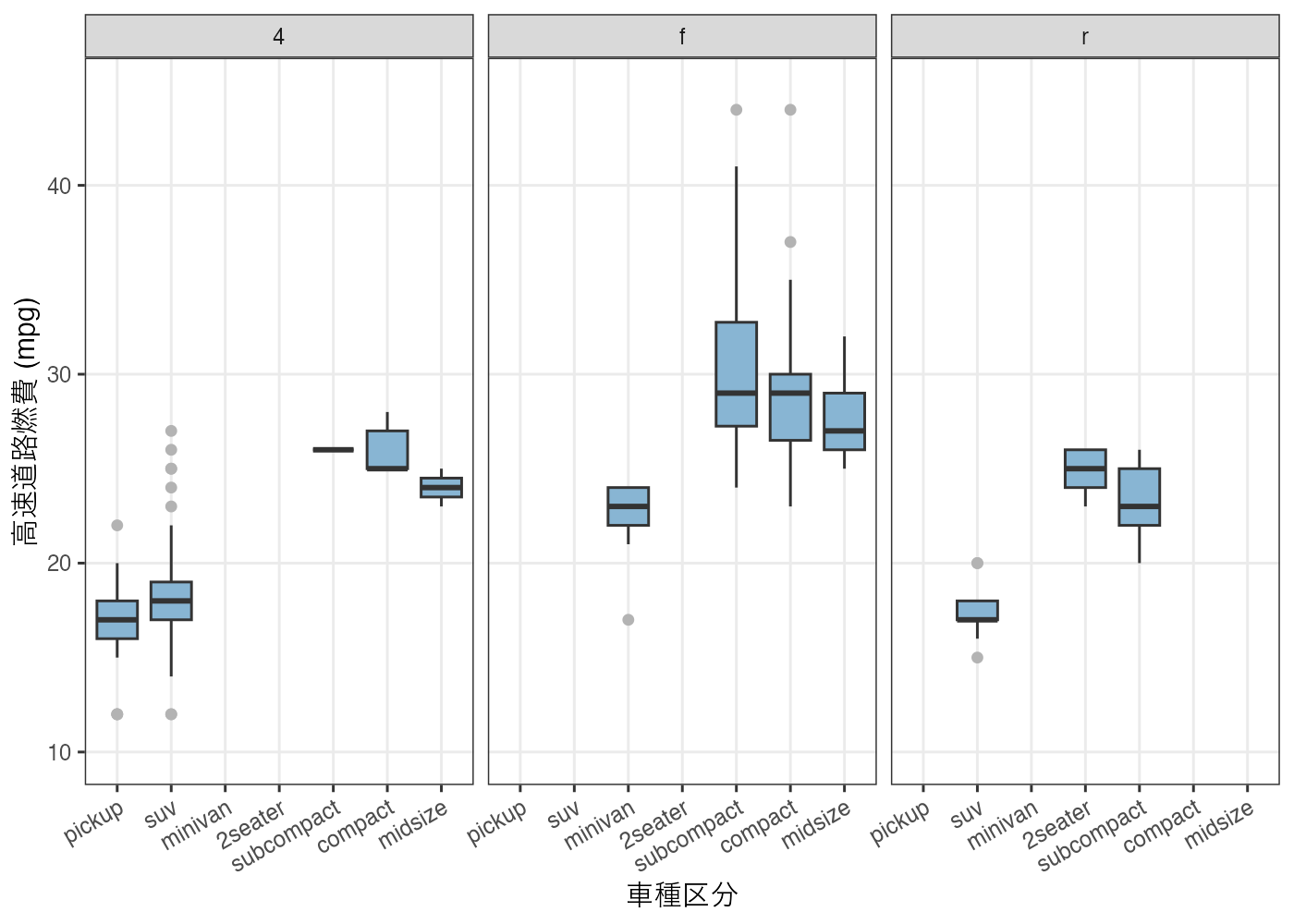
駆動方式によって燃費の良さに違いはあるでしょうか?
- 全ての組み合わせでデータ存在していないので比較が難しいですが、全般的には前輪駆動 (f) の車種の燃費が良いことが示唆されます。
例外的に燃費の良い SUV 車はどの駆動方式に多く見られますか?
- 燃費の良い外れ値のSUV車はすべて四輪駆動車であることがわかります。
[課題B]
# STEP 2 課題 B: 集計データの計算
library(ggplot2)
dat = mpg
# 1. table()でメーカーとクラスごとの車種数をクロス集計する
# 結果は matrix の形になる
table_counts = table(dat$manufacturer, dat$class)
# 2. ggplotで扱えるデータフレーム形式に変換する
# 結果のdf_countは、manufacturer, class, count の3列を持つ
df_count = as.data.frame(table_counts)
names(df_count) = c("manufacturer", "class", "count")
# 3. 集計データから棒グラフを描画(合計値順に並べ替えもしている)
fig = ggplot(df_count, aes(x = reorder(manufacturer, count, sum), y = count, fill = class)) +
geom_col(color = "black", linewidth = 0.3) +
labs(x = "メーカー名", y = "車種数 (カウント)") +
theme_bw() +
theme(
axis.text.x = element_text(angle = 45, hjust = 1)
)
plot(fig)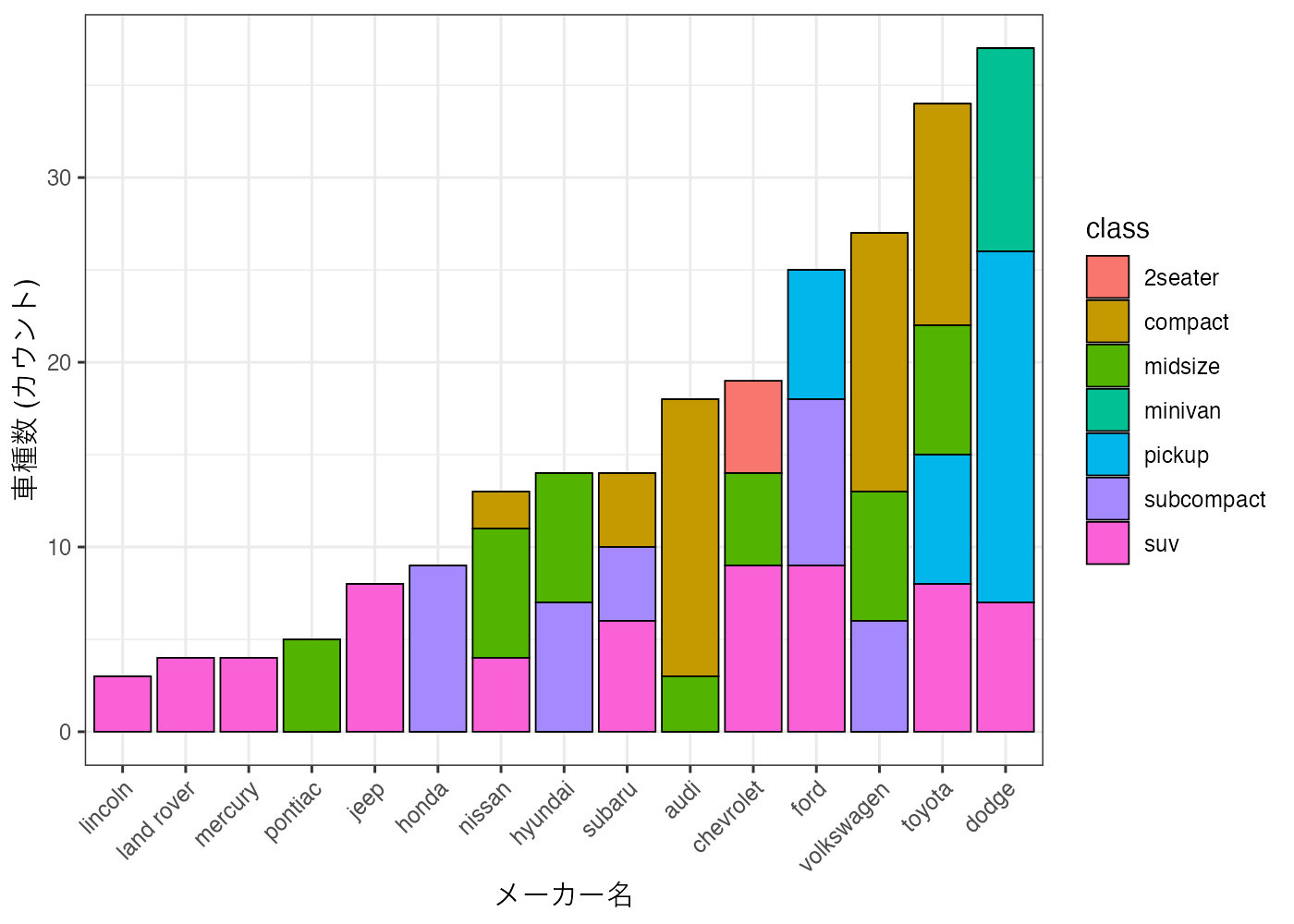
- 上記の解答ではtable関数を使って集計データを作成し、それを使ってグラフを作成しています。
- 合計数順に棒を並べ替えるとグラフが見やすいので、reorder関数を使ってそれを実現しています。
fig_bar = ggplot(dat, aes(x = reorder(manufacturer, manufacturer, length), fill = class)) +
geom_bar(color = "black", linewidth = 0.3) +
labs(x = "メーカー名", y = "車種数 (カウント)") +
theme_bw() +
theme(
axis.text.x = element_text(angle = 45, hjust = 1),
panel.grid.minor = element_blank()
)
plot(fig_bar)
グラフから、SUV は特定の企業が市場をリードしているというよりは、規模の小さなところも含めさまざまなメーカーから車が販売されていることがわかります。このような多様な選択肢の存在する市場で自社の車を伸ばしていくには、燃費の良さなど、特別に優れた特徴を明確にアピールする必要があると考えられます。